
Researcher encourages journalists to understand varied risks posed by uses of AI
Critical journalistic reporting on machine learning requires an understanding of data leakage. This image was created with the assistance of DALL·E 3.
Amid the growing enthusiasm for artificial intelligence (AI), journalists must go beyond superficial reporting and ask probing questions that challenge assumptions about AI, an AI researcher urged science writers attending the Council for the Advancement of Science Writing’s New Horizons in Science briefings at the ScienceWriters2023 conference Oct. 9 in Boulder, Colo.
Sayash Kapoor, an AI researcher and PhD student at the Princeton Center for Information Technology Policy and co-author of the forthcoming book AI Snake Oil, encouraged journalists to focus in particular on the vulnerability that comes from a phenomenon known as data leakage, which needs to be better understood to ensure the correct and ethical application of AI. (A video recording of Kapoor’s presentation is available.)
Journalists, Kapoor noted, play a pivotal role in influencing the way the public perceives AI. The hype surrounding AI, he said, often stems from sensationalism and a lack of context, which can result in misleading information. Journalists have a responsibility to investigate and report on the ethical implications of AI. After explaining how AI systems learn by ingesting large data sets, he said: “One very basic question to ask of any AI system is, what’s in the training data? And more particularly, how well does it match what the model will actually be used for? Because at the end of the day, all you’re using it for is real-world tasks, which it might not always resemble.”
Following OpenAI’s launch of the ChatGPT chatbot for public use, public attention has turned toward generative AI, which uses language models to generate textual responses based on user inputs. This has brought both excitement and concern to the public. Kapoor’s work, though, is focused on a different group of technologies known as predictive AI.
Like generative AI, predictive AI is based on machine learning, the process of improving a model’s performance by training an algorithm with data. Predictive AI systems, widely used in computational science, social science, medicine, and government, learn from experience to analyze large datasets, identify patterns, and make predictions or decisions.
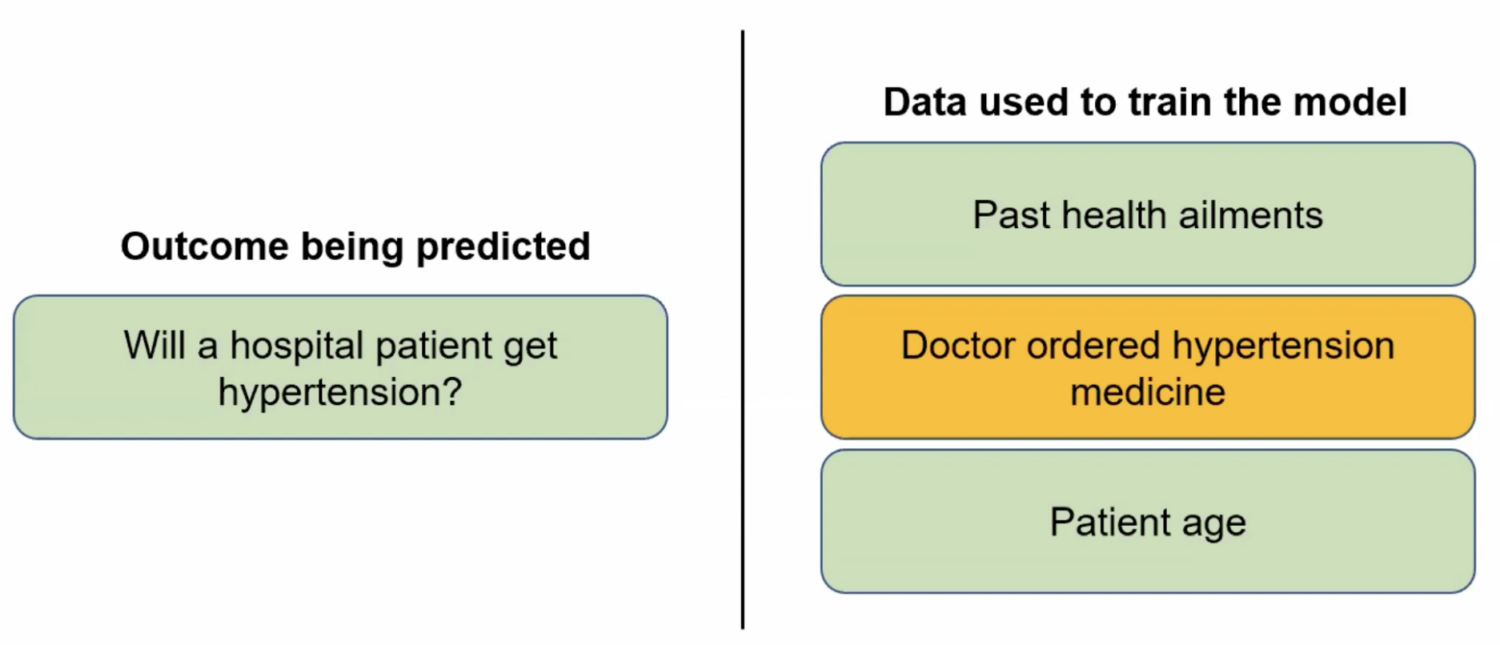
Kapoor explained that building predictive AI involves splitting data into training and test sets to develop a predictive model and evaluate its performance. However, a significant challenge in machine learning is data leakage, which occurs when the system’s training and test data are not adequately separated. When there is an unintended mixing of information between training and test datasets—for example, when test data are included in the training set, when future data are used to predict the past, or when the model is exposed to inappropriate information—the result can be inflated accuracy scores and misrepresentations of the AI system’s actual capabilities.
Kapoor illustrated this concern with an example involving a machine learning system designed to predict whether a patient admitted to a hospital will develop hypertension. The model was trained on data consisting of the patient’s medical history, age, and whether they had been prescribed hypertension medication by a doctor. The inclusion of the doctor’s prescription, he pointed out, essentially made the predictive AI mimic the doctor’s diagnosis, rather than provide an independent prediction. Such data leakage, he said, can distort results, misguide researchers, and create a false sense of superiority.
In another case from 2017, Epic, a healthcare technology company, introduced a sepsis prediction algorithm. Long a major cause of mortality in U.S. hospitals, sepsis has been implicated in one in five hospital deaths globally. Epic’s algorithm originally boasted a seemingly impressive accuracy metric score of 0.76 to 0.88. (A score of 0.5 is random.) These scores sparked hopes of improved sepsis management. However, in 2021, an investigation in nearly 30,000 hospitalized patients revealed a different reality: The accuracy metric score was 0.63, which is not far from random predictions. The algorithm was discontinued in October 2022.

Ethical considerations vary depending on the type of AI in question, Kapoor said: “More important is the distinction between what different types of AI are actually used for in the real world, and that’s where we can understand where a lot of the confusion around modern AI methods comes from.” Understanding the distinctions between different types of AI is crucial to prevent this confusion. Kapoor distinguished between generative AI; perception AI, which exhibits flexibility in processing various inputs for tasks such as speech-to-text translation; and predictive AI, which learns from examples, as illustrated in the hypertension prediction algorithm.
Generative and perception AI, Kapoor said, raise ethical concerns when they perform exceptionally well—instances where chatbots generate human-like essays, albeit riddled with misinformation. By contrast, predictive AI raises concerns when it underperforms. Journalists, he said, need to be critical in reporting and understanding that AI models use different language models if they are to help the public navigate the complexities of AI, dispel the hype, and harness its potential for the betterment of society.